


本文更新于: 2024年5月24日
Chenyme AAVT 是一个简单易用的全自动视频(音频)识别、翻译工具,快速识别声音并翻译生成字幕文件,然后将翻译后的字幕与原视频合并,生成翻译后的视频。
主要基于 OpenAI 开发的 Whisper 来识别声音和 LLMs 辅助翻译字幕 ,利用 Streamlit 搭建快速使用的 WebUI 界面,以及 FFmpeg 来实现字幕与视频的合并。
这个工具对于需要快速翻译视频内容的用户来说非常有用,尤其是那些希望自动化处理视频翻译任务的人。它提供了一个强大的工具集,以支持视频翻译的整个工作流程。
工具截图
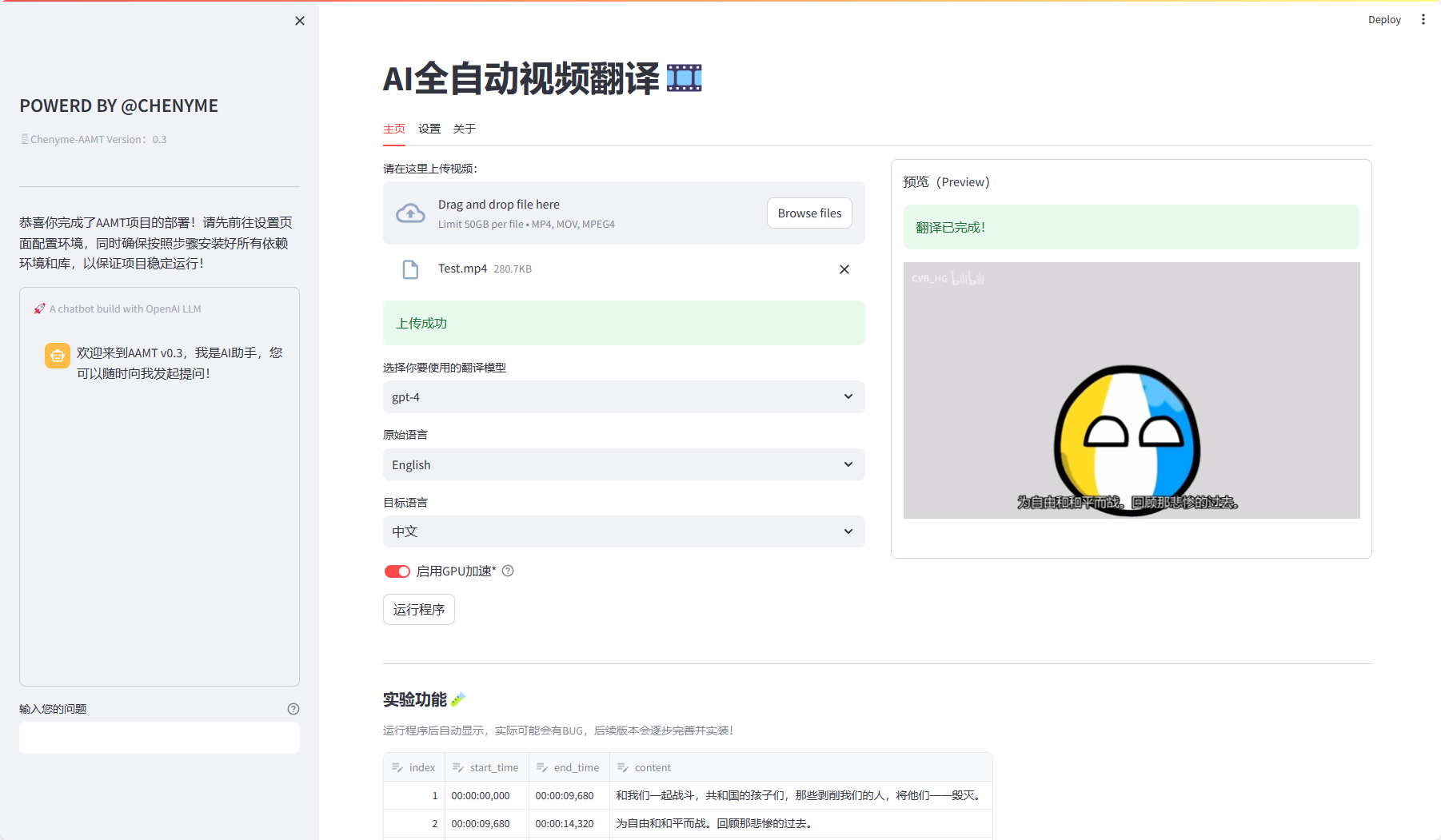
功能特色
- 视频/音频识别:利用 OpenAI 开发的 Whisper 模型来识别视频中的声音。
- 翻译字幕:结合大型语言模型(LLMs)辅助翻译字幕,以生成准确的翻译。
- WebUI界面:使用 Streamlit 构建的快速使用的 Web 用户界面,方便用户操作。
- 视频处理:通过 FFmpeg 实现字幕与视频的合并,生成翻译后的视频文件。
- 调用 openai:支持直接调用 OpenAI 的 API 进行翻译。
- 本地运行 faster-whisper:可以在本地运行 faster-whisper 模型进行声音识别。
- GPU 加速:支持 GPU 加速,提高翻译和处理速度。
- VAD 辅助:支持声音活动检测(VAD)辅助,以更准确地识别语音部分。
- 多种翻译支持:支持 ChatGPT、KIMI、DeepSeek 等多种翻译服务。
- 本地翻译模型:允许使用本地部署的大型语言模型进行翻译。
- 多语言识别与翻译:支持识别和翻译多种语言。
- 多种字幕格式:支持输出多种字幕格式,如 SRT、ASS 等。
- 字幕编辑功能:用户可以对生成的字幕进行修改、微调和预览。
- 音频 AI 总结与问答:支持对音频内容进行 AI 总结和问答。
项目地址
https://github.com/Chenyme/Chenyme-AAVT
本文链接:Click here to view the current URL
声明:本站为个人非盈利博客,资源均网络收集且免费分享无限制,无需登录。资源仅供测试学习,请于24小时内删除,任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集。请支持正版!如若侵犯了您的合法权益,可联系我们处理。
