


本文更新于: 2024年3月29日
一个基于 Tesseract 的多种语言模型 OCR 屏幕截图工具,它捕捉信息而不是图片。支持 Linux、macOS、Windows 等桌面系统。
经检测是在设备上执行的,不会上传截图、收集遥测数据,支持具有任意缩放设置的任意数量显示器。
支持离线使用,阿喵我测试了下,发现英文识别很好,如果想要识别中文或者韩语,日文等,则需要去设置里下载添加语言。整体体验效果不错
软件截图
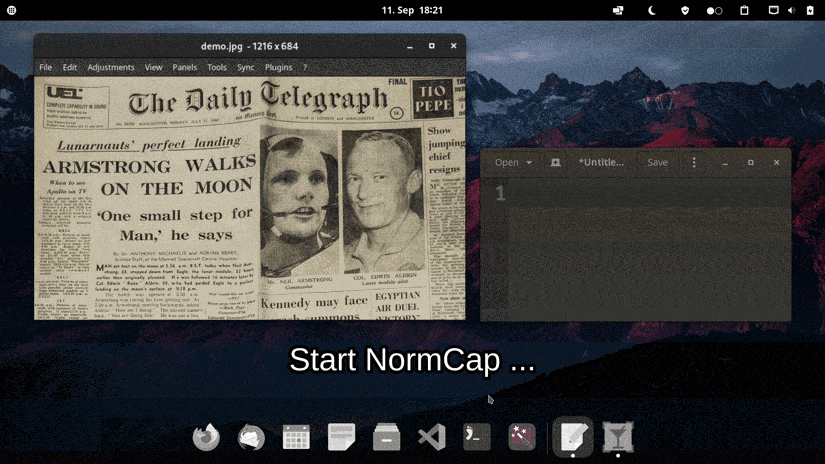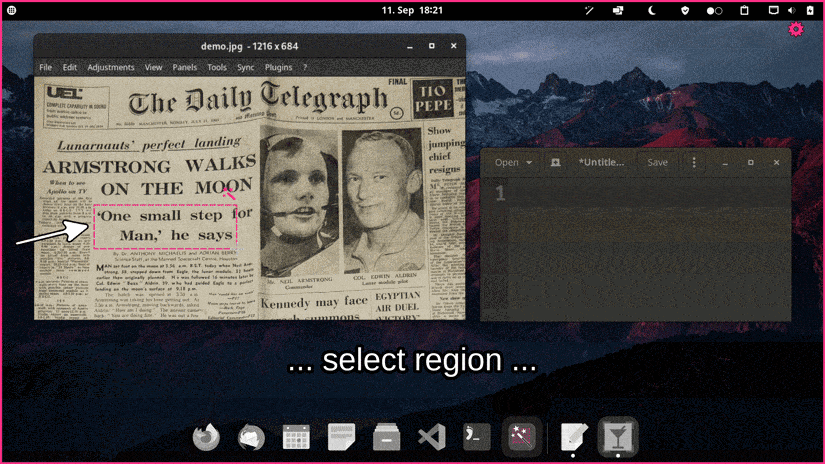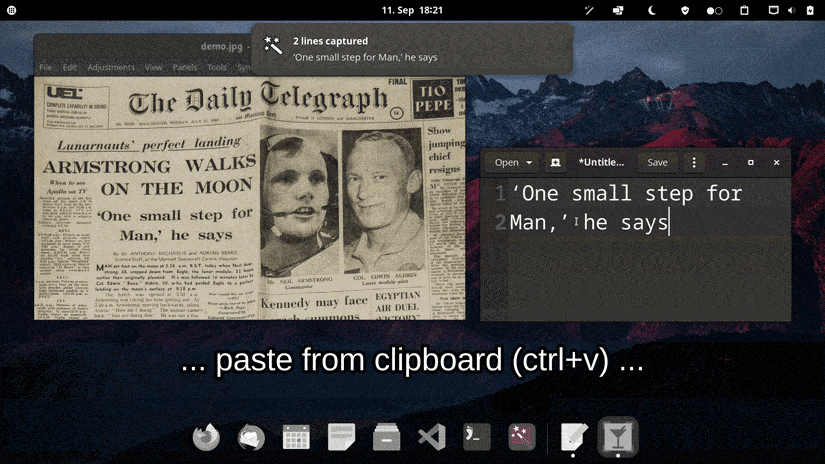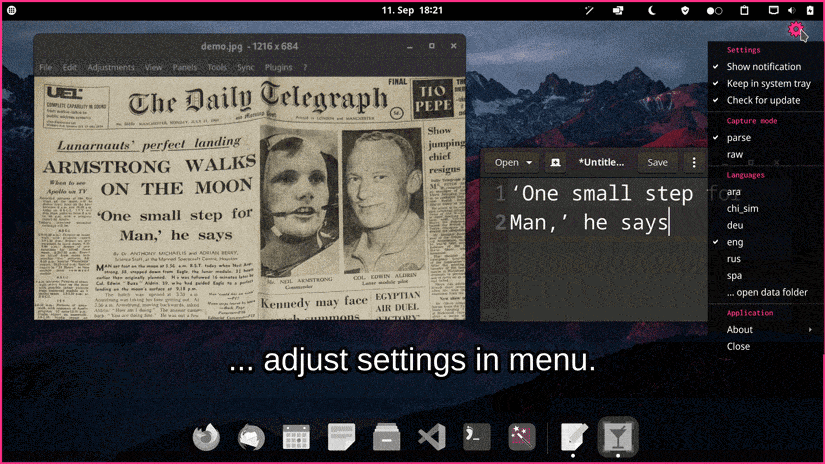
软件特色
多种语言
使用 Tesseract 的多种语言模型进行文本检测。
隐私第一
检测是在您的设备上执行的,并且不会收集遥测数据。
启发式解析
邮件地址和 URL 会被检测到并进行相应的处理。
多显示器支持
支持具有任意缩放设置的任意数量的显示器。
跨平台
适用于 Windows& 苹果系统与Linux。
免费和开源
NormCap 根据 GPLv3 获得许可,并可在GitHub上获取。
软件下载
GitHub| https://github.com/dynobo/normcap/releases
官网| https://dynobo.github.io/normcap/
本文链接:Click here to view the current URL
声明:本站为个人非盈利博客,资源均网络收集且免费分享无限制,无需登录。资源仅供测试学习,请于24小时内删除,任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集。请支持正版!如若侵犯了您的合法权益,可联系我们处理。
