


本文更新于: 2023年11月19日
,「py Corrector」是一个中文文本纠错工具。支持中文音似、形似、语法错误修正,基于python3开发。
「py Corrector」实现了Kenlm、ConvSeq2Seq、BERT、MacBERT、ELECTRA、ERNIE、Transformer等多个模型的文本纠错,并在SigHAN数据集评估各模型的效果。
项目介绍
中文文本纠错任务,常见错误类型:
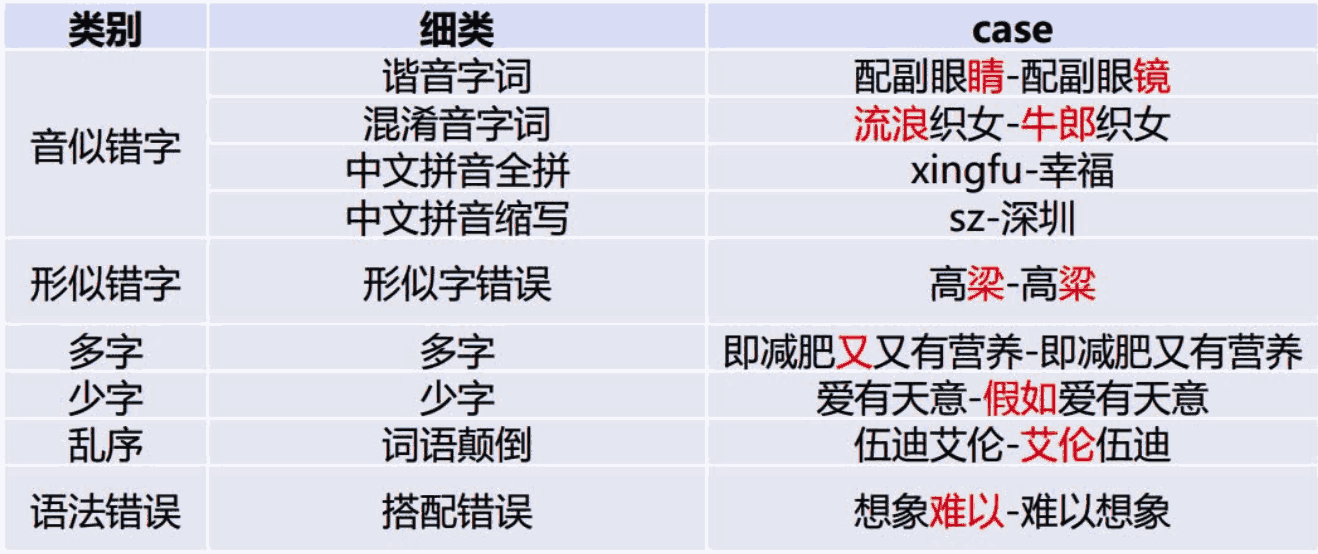
当然,针对不同的业务场景,这些问题并不一定全部存在,比如拼音输入法、语音识别校对关注音似错误;五笔输入法、OCR校对关注形似错误,搜索引擎查询纠错关注所有错误类型。
本项目重点解决其中的“音似、形字、语法、专名错误”等类型。
项目演示
官方演示:https://www.mulanai.com/product/Corrector/
Colab在线演示:https://colab.research.google.com/drive/1zvSyCdiLK_rglfXcIgc539K_Z7bIMpu0?usp=sharing
HuggingFace 演示:https://huggingface.co/spaces/shibing624/py
项目链接
「注意」:源项目在Github平台上,你可能需要一些特殊方法才能正常访问,同时源项目为全英文,你可能需要实时翻译软件才可流畅阅读。
地址:https://github.com/shibing624/pycorrector
本文链接:Click here to view the current URL
声明:本站为个人非盈利博客,资源均网络收集且免费分享无限制,无需登录。资源仅供测试学习,请于24小时内删除,任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集。请支持正版!如若侵犯了您的合法权益,可联系我们处理。
