


本文更新于: 2023年11月15日
ChatAnything:可以与 LLMs 增强角色进行视频聊天
你可以通过文本描述,生成具有独特个性、外观和声音的虚拟角色人物。
而且这个人物不仅有自己的外观,还有独特的声音和个性,还可以跟你进行语音对话和视频聊天。😅
ChatAnything的工作原理基于几个关键的技术组件,这些组件共同协作,使得用户能够通过文本描述来创建和动画化个性化的虚拟角色。
项目截图
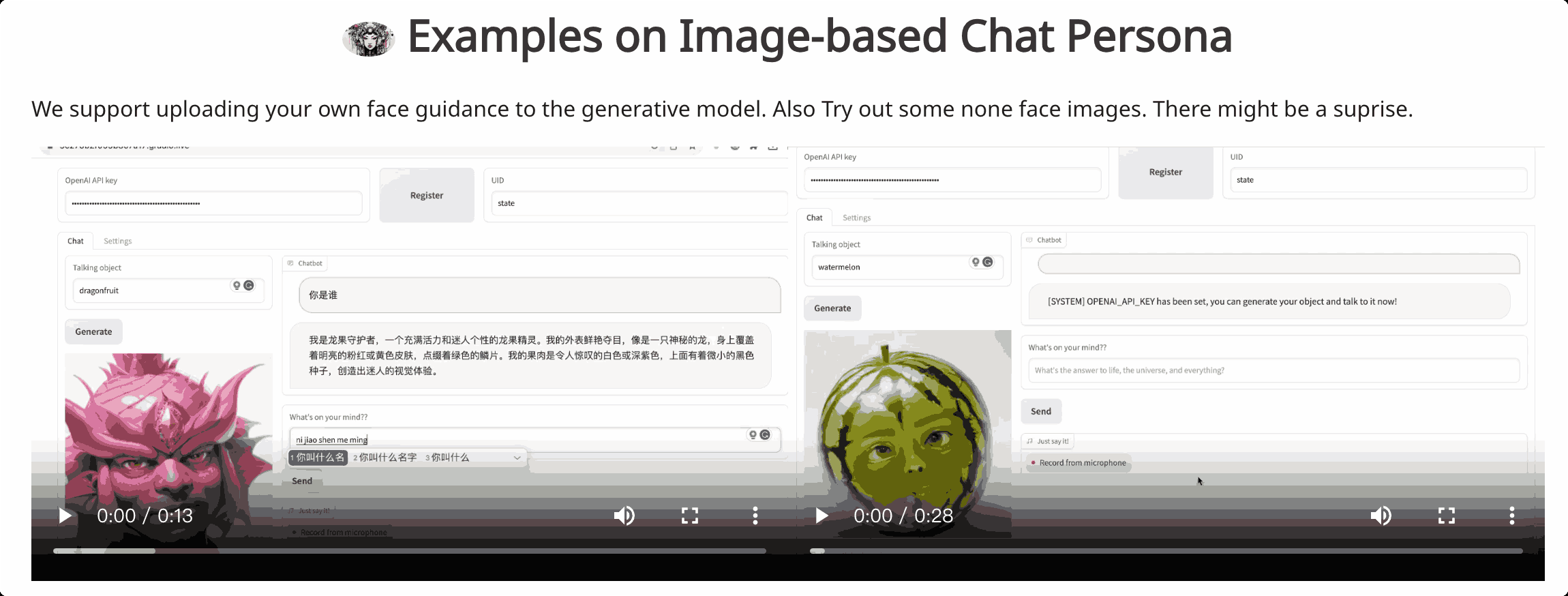
项目介绍
以下是其主要工作流程和组件:
1、生成个性化角色:
•用户提供一个文本描述,定义想要创建的角色的特征和个性。
•大语言模型(LLM)根据这些描述生成一个具有特定个性的角色。
2、声音和外观的生成:
•声音混合(MoV):这一部分利用文本到语音(TTS)技术。根据用户的文本描述,系统自动选择最匹配的声音特征,为角色生成独特的声音。
•扩散器混合(MoD):结合了文本到图像生成技术和说话头部算法。这一步骤简化了生成说话对象的外观的过程。
3、动画化角色:
•一旦角色的个性、声音和外观被生成,系统使用这些信息来动画化角色。
•这包括将声音信号与生成的图像相结合,使角色能够根据用户的指令进行“说话”和“表现”。
4、面部运动的生成:
•为了使生成的角色更加逼真,系统还包括了面部运动的生成。
•这一部分涉及到像素级引导,它在图像生成阶段注入人脸标记,以确保面部运动的自然性和准确性。
ChatAnything的目标是通过文本输入,使用户能够以任何人格化的方式动画化任何事物。
项目地址
项目地址:https://chatanything.github.io
论文:https://arxiv.org/abs/2311.06772
GitHub:https://github.com/zhoudaquan/ChatAnything
在线演示:https://26fed97b4a7706bed0.gradio.live
声明:本站为个人非盈利博客,资源均网络收集且免费分享无限制,无需登录。资源仅供测试学习,请于24小时内删除,任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集。请支持正版!如若侵犯了您的合法权益,可联系我们处理。
